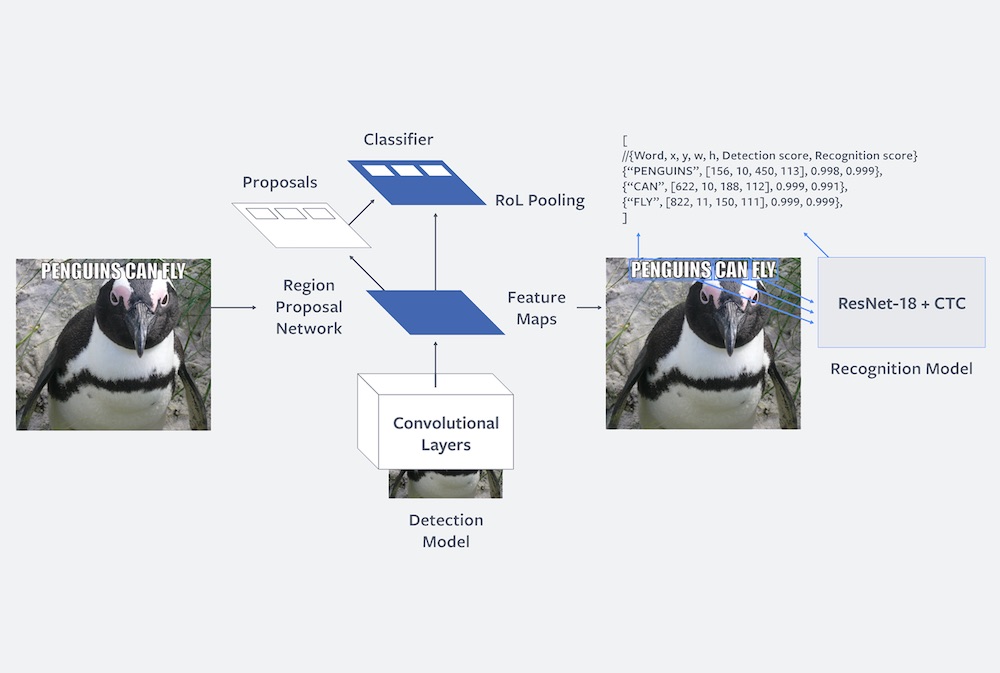
Facebook 的检查人员无法审阅人们在渠道上发布的每一张图片,因而 Facebook 期望经过人工智能来协助他们。在一篇
博客文章
中,Facebook 介绍了一个名为 Rosetta 的体系,它可以使用机器学习来辨认图画和视频中的文本,然后将其转录为机器可读的内容。特别地,Facebook 发现这个东西有助于在表情包上转录文本。文本转录东西并不是什么新鲜事,但 Facebook 却面临着不同的应战,由于其渠道量级巨大,以及其上的图画品种繁复。依据官方说法,Rosetta 现在现已上线,每天会从 Facebook 和 Instagram 上抓取 10 亿个图画和视频帧文本进行转录。
现在还不清楚 Facebook 正在对这些数据进行怎样的处理。文章指出,这关于相片查找和屏幕阅读器等基本功用十分有用。但看起来 Facebook 也开端把它放在更大的目标上,比方弄清楚什么样的内容更吸引人,更重要的是,可以找出哪些表情包、图片或视频中存在仇视、凌辱等不妥言辞。
Facebook表明,文本提取和机器学习正在被用于“主动辨认违背咱们的仇视言辞方针的内容”,并且该体系还支撑多语言。鉴于 Facebook 众所周知的内容审阅问题,一个可以主动符号可能有问题的图画的功用,关于 Facebook 来说应该会很有用。